

使用BeautifulSoup在Python中进行网页爬虫
什么是网页抓取?
网页抓取被定义为"从网站或互联网中提取数据",它就是这样 - 使用代码自动读取网站、搜索某些内容或查看页面源代码,以便从中保存某种信息。
这在各个领域都有应用,从谷歌机器人索引网站,到收集体育统计数据,再到将股票价格保存到Excel电子表格 - 选择真的是无限的。如果有你感兴趣的网站、页面或搜索词,并希望获得相关更新,那么这篇文章就是为你准备的 - 我们将看看如何使用 requests 和 BeautifulSoup 库来用Python从网站收集数据,你可以轻松地将学到的技能转移到抓取任何你感兴趣的网站。
我们将使用哪些工具?
Python是抓取互联网数据的首选语言,而 requests 和 BeautifulSoup 这些库是完成该任务的首选Python包。使用 requests,你可以轻松抓取任何网站,并以多种方式读取其数据,从HTML到JSON。由于大多数网站都是用HTML构建的,我们将从页面中提取所有HTML,然后使用来自 BeautifulSoup 的 bs4 包来解析HTML并在其中找到我们要寻找的数据。
要求
为了能够跟上进度,你需要安装Python、 requests,和 BeautifulSoup 。
-
Python:你可以从 官方网站下载最新版本的Python,尽管你很可能已经安装了它。
-
requests:如果你的Python版本 >= 3.4,你就已经安装了pip。然后你可以在命令行中通过在任何目录下输入pip来使用python3 -m pip install requests。 -
BeautifulSoup:这是打包在bs4下的,但你可以轻松地用python3 -m pip install beautifulsoup4.
编程
安装它 我相信学习编程的最佳方式是通过实践和构建项目,所以我强烈建议你在你喜欢的文本编辑器(我推荐Visual Studio Code)中跟随我一起学习如何通过示例使用这两个库。
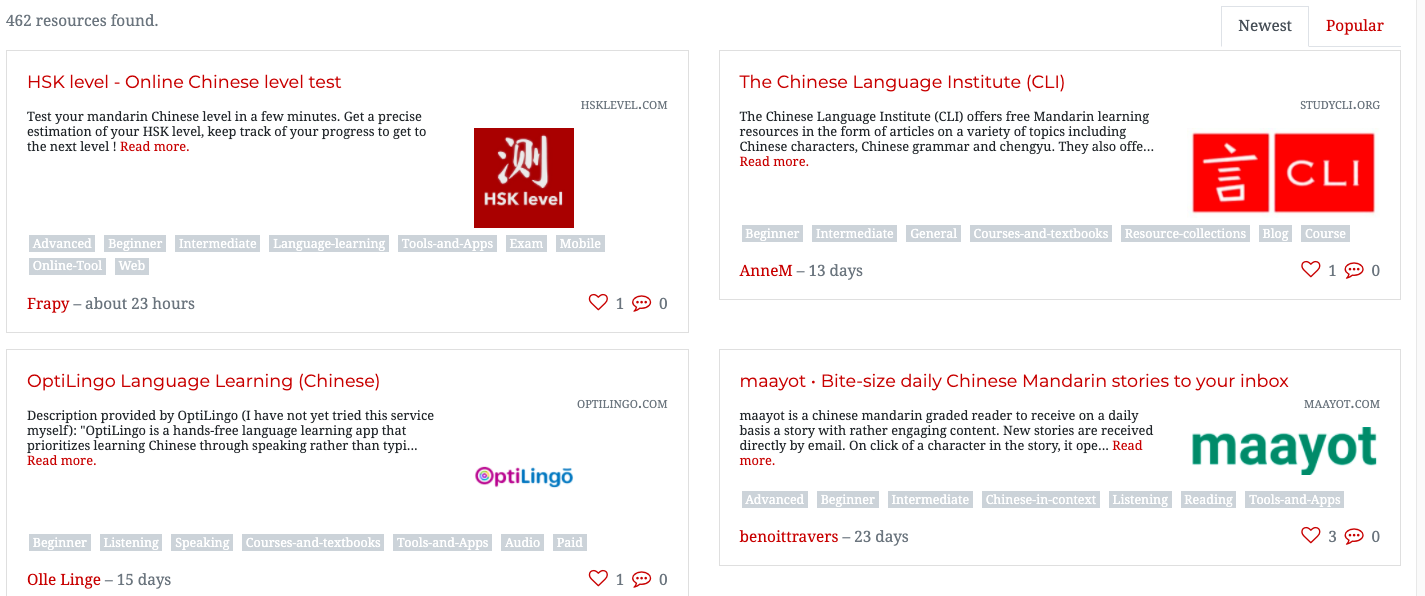
由于我正在学习普通话,我认为构建一个生成普通话资源链接列表的爬虫会很合适。幸运的是,我事先做了一些研究,发现 有 网上有一个网站以卡片式列表的形式存储普通话资源。然而,这些资源分布在近十几个页面上,以卡片形式呈现,而且很多链接已经失效。我们将要爬取这些链接的网站是一个知名的普通话学习网站,您可以在这里查看资源列表: https://challenges.hackingchinese.com/resources.
因此,在这个项目中,我们将从该列表中爬取有效的链接,并将它们保存到我们计算机上的一个文件中,这样我们以后就可以在闲暇时浏览它们,而不必点击网站上的每张卡片。整个程序只有大约40行代码,我们将分三个独立的步骤来完成这个项目。
分析网站
在我们开始实际编程之前,我们需要看一下 哪里 数据存储在网站上。这可以通过"检查"页面来完成。你可以通过在页面内任意位置右键单击然后选择"检查"来检查页面。如果你选择了这个选项,它会在屏幕底部显示页面的源代码,一堆看起来令人生畏的HTML。别担心—— BeautifulSoup 库将使这变得简单。
我们将"检查"网站上的第一个结果,即在 https://challenges.hackingchinese.com/resources,也就是 HSK level — Online Chinese level test。为此,我们需要将鼠标放在我们想要抓取的内容上方——也就是标题,因为它也是一个链接——然后点击"检查",这将打开源代码并将我们移动到我们想要的确切位置——链接处。
如果你这样做,你应该看到类似下面的内容:
class="card-title" style="font-size: 1.1rem">
href="http://www.hsklevel.com">HSK level — Online Chinese level test
好消息!看起来每个链接都在h4标题内。每当我们抓取网站数据时,我们需要查看该数据的唯一"标识符"。在这种情况下,它是h4标题,因为网站上没有其他与链接无关的h4标题。另一个选择可能是基于 font-size 或 class 的 card-title进行搜索,但我们将选择h4标题,因为这是最简单的。
抓取资源链接
现在我们已经弄清楚了网站源码的样子,我们需要开始实际抓取内容了。我们将把每个链接保存到设备上名为 links.txt,只需要几十行代码就能完成任务。
让我们开始吧。
- 导入库
我们需要上述库来运行程序。创建一个名为scrape_links.py的新文件,并写入以下内容:
import requests, time 导入 bs4 import BeautifulSoup - 抓取网站
由于 网站 的资源分布在几个页面上,因此将其放在一个函数中进行抓取是有意义的,这样我们就可以重复使用它。让我们将这个函数命名为extract_resources,它将有一个定义页码的参数。
def extract_resources(page: int -> None): # use an f-string to access the correct page page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}) soup = BeautifulSoup(page.content, 'html.parser')我们使用
soup变量来保存网站的BeautifulSoup对象。我们用html.parser将其转换为HTML,我们转换的数据是page变量的内容。links = soup.find_all('h4')我们将使用
BeautifulSoup来查找所有作为标题的HTML,并将它们与其子HTML(在这种情况下是链接)一起保存在名为links的列表中。 - 收集我们的数据
for i 在 range(len(links)): try: if links[i]['class'] == ['card-title']: true_links.append(links[i]) except: pass在第一行,我们遍历
links中的每个h4标题。我们检查它的类是否是card-title,就像我们在 分析网站,为了确保我们避免任何不是卡片的h4标题 — 以防万一。如果是带链接的卡片相关h4,那么我们将把它附加到之前空的列表中true_links与所有 正确 h4一起。
最后,我们将把这个包裹在一个try: except:循环中,以防h4没有case,以防止程序崩溃,因为BeautifulSoup无法处理请求。 - 保存链接
# open file with w+ (generate it if it does not exist) file = open("links.txt", "w+") for i 在 range(len(true_links)): file.write(str(list(true_links[i].children)[0]['href']) + '\n') file.close()与其打印出列表,不如保存它,这样我们就不需要多次运行Python文件,并且可以以更容易查看的格式保存。
首先,我们打开文件,我们以w+模式打开它,这样如果文件不存在,我们可以用它的名字生成一个空白文件。
其次,我们遍历true_links列表。对于每个元素,我们使用file.write()将其链接写入文件。当我们最初分析网站时,我们看到链接是h4 HTML标题的子元素。因此,我们使用BeautifulSoup来访问true_links[i]的第一个子元素,我们需要将其包装在一个列表中,因为它否则是一个Python对象。
此时,我们有了list(true_links[i].children)[0]。然而,我们要找的是子元素的实际链接。我们不要Text,而是只要链接,我们可以用['href']. 一旦我们有了这个,我们需要将整个内容包裹在一个字符串中,以便将其作为字符串输出,然后添加'\n'以确保每个链接在输出时都在新的一行上file.write()最后,我们执行
以关闭我们打开的文件。file.close()如果运行程序并等待几分钟,你应该会发现现在有一个名为
的文件,其中包含links.txt与 我们正在抓取的网站维护状况并不太好,一些链接已过时或完全失效。因此,在这个可选步骤中,我们将看到抓取的另一个方面,它返回每个网站的状态代码,如果是404(表示未找到),则将其丢弃。 在结束之前,我们将看到另一种使用
库的方法,即通过检查每个链接的状态。requests数百个
额外内容:删除失效链接
我们需要稍微修改上面步骤4中使用的代码。我们不会简单地遍历链接并将它们写入文件,而是首先确保它们没有失效。
我们做了一些更改 - 让我们来看看。
file = open("links.txt", "w+")
for i 在 range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
我们创建了一个
-
response检查链接状态码的变量——基本上是检查链接是否仍然存在。这可以通过有用的方法来完成。我们获取我们试图追加的相同链接,即网站URL,并给它5秒钟的响应时间,重定向的机会,并允许它向我们发送文件(我们不会下载),使用requests.get()我们通过查看响应是否为404来检查响应。如果不是,那么我们就写入链接,但如果是,那么我们什么也不做,不将链接写入文件。这是通过条件语句来完成的stream = True. - 最后,我们将整个过程包裹在一个try-except循环中。这是因为如果页面加载缓慢、无法访问或连接被拒绝,通常程序会在异常中崩溃。然而,由于我们将其包裹在这个循环中,所以在发生异常的情况下什么也不会发生,只会被忽略。
if response != 404. - 就是这样!如果你运行代码(并让它继续运行,因为要检查数百个链接,可能需要半个小时),当它完成时,你会得到一组漂亮的几百个有效的资源链接!
在这篇文章中,我们学会了如何: requests 查看页面源代码
完整代码
# grab the list of all the resources at https://challenges.hackingchinese.com/resources
import requests, time
导入 bs4 import BeautifulSoup
# links that hold the correct content, not headers and other HTML
true_links = []
def extract_resources(page: int) -> None:
page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}')
soup = BeautifulSoup(page.content, 'html.parser')
# links are stored within a unique header on each card
links = soup.find_all('h4')
for i 在 range(len(links)):
try:
if links[i]['class'] == ['card-title']:
true_links.append(links[i])
except:
pass
for i 在 range(1, 10):
extract_resources(i) # 9 different pages with info
file = open("links.txt", "w+")
for i 在 range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
结论
- 抓取网站特定数据
- 用Python写入文件
- 检查死链接
虽然我们只是触及了使用适当库在Python中进行网络抓取的表面,但我希望即使是这个简短的介绍也能教会你如何利用编程的力量自动抓取网站。我强烈建议你查看 requests 和 BeautifulSoup 的官方文档,如果你想深入了解数据抓取的世界,看看有什么数据 你 可以从网上收集并用于你自己的项目。
如果你正在抓取什么或需要任何更多帮助,请在评论中告诉我!
编码愉快!
留言